
 |
Today we are announcing the rename of Amazon Kinesis Data Analytics to Amazon Managed Service for Apache Flink, a fully managed and serverless service for you to build and run real-time streaming applications using Apache Flink.
We continue to deliver the same experience in your Flink applications without any impact on ongoing operations, developments, or business use cases. All your existing running applications in Kinesis Data Analytics will work as is without any changes.
Many customers use Apache Flink for data processing, including support for diverse use cases with a vibrant open-source community. While Apache Flink applications are robust and popular, they can be difficult to manage because they require scaling and coordination of parallel compute or container resources. With the explosion of data volumes, data types, and data sources, customers need an easier way to access, process, secure, and analyze their data to gain faster and deeper insights without compromising on performance and costs.
Using Amazon Managed Service for Apache Flink, you can set up and integrate data sources or destinations with minimal code, process data continuously with sub-second latencies from hundreds of data sources like Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK), and respond to events in real-time. You can also analyze streaming data interactively with notebooks in just a few clicks with Amazon Managed Service for Apache Flink Studio with built-in visualizations powered by Apache Zeppelin.
With Amazon Managed Service for Apache Flink, you can deploy secure, compliant, and highly available applications. There are no servers and clusters to manage, no compute and storage infrastructure to set up, and you only pay for the resources your applications consume.
A History to Support Apache Flink Since we launched Amazon Kinesis Data Analytics based on a proprietary SQL engine in 2016, we learned that SQL alone was not sufficient to provide the capabilities that customers needed for efficient stateful stream processing. So, we started investing in Apache Flink, a popular open-source framework and engine for processing real-time data streams.
Since we launched Amazon Kinesis Data Analytics based on a proprietary SQL engine in 2016, we learned that SQL alone was not sufficient to provide the capabilities that customers needed for efficient stateful stream processing. So, we started investing in Apache Flink, a popular open-source framework and engine for processing real-time data streams.
In 2018, we provided support for Amazon Kinesis Data Analytics for Java as a programmable option for customers to build streaming applications using Apache Flink libraries and choose their own integrated development environment (IDE) to build their applications. In 2020, we repositioned Amazon Kinesis Data Analytics for Java to Amazon Kinesis Data Analytics for Apache Flink to emphasize our continued support for Apache Flink. In 2021, we launched Kinesis Data Analytics Studio (now, Amazon Managed Service for Apache Flink Studio) with a simple, familiar notebook interface for rapid development powered by Apache Zeppelin and using Apache Flink as the processing engine.
Since 2019, we have worked more closely with the Apache Flink community, increasing code contributions in the area of AWS connectors for Apache Flink such as those for Kinesis Data Streams and Kinesis Data Firehose, as well as sponsoring annual Flink Forward events. Recently, we contributed Async Sink to the Flink 1.15 release, which improved cloud interoperability and added more sink connectors and formats, among other updates.
Beyond connectors, we continue to work with the Flink community to contribute availability improvements and deployment options. To learn more, see Making it Easier to Build Connectors with Apache Flink: Introducing the Async Sink in the AWS Open Source Blog.
New Features in Amazon Managed Service for Apache Flink
As I mentioned, you can continue to run your existing Flink applications in Kinesis Data Analytics (now Amazon Managed Apache Flink) without making any changes. I want to let you know about a part of the service along with the console change and new feature, a blueprint where you create an end-to-end data pipeline with just one click.
First, you can use the new console of Amazon Managed Service for Apache Flink directly under the Analytics section in AWS. To get started, you can easily create Streaming applications or Studio notebooks in the new console, with the same experience as before.
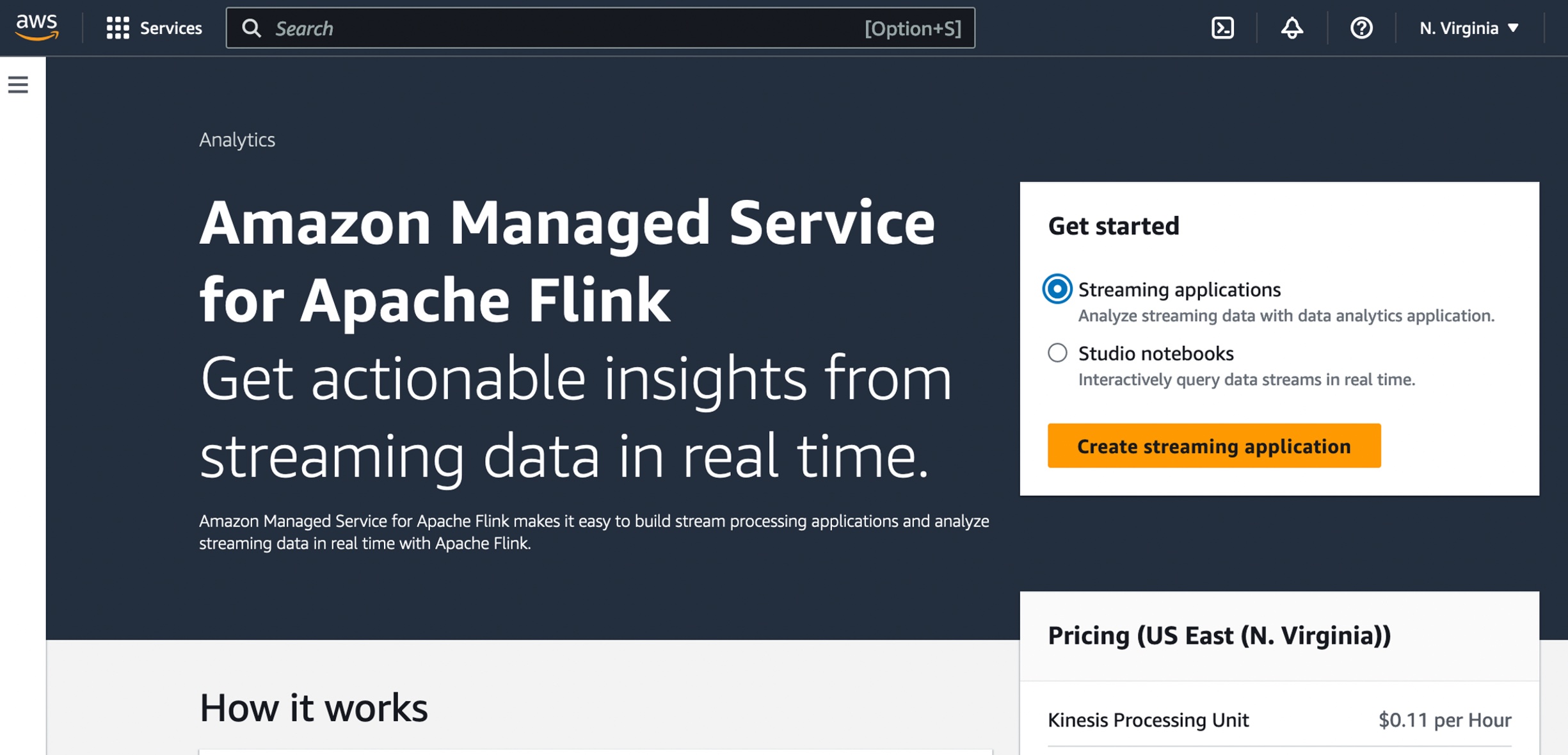
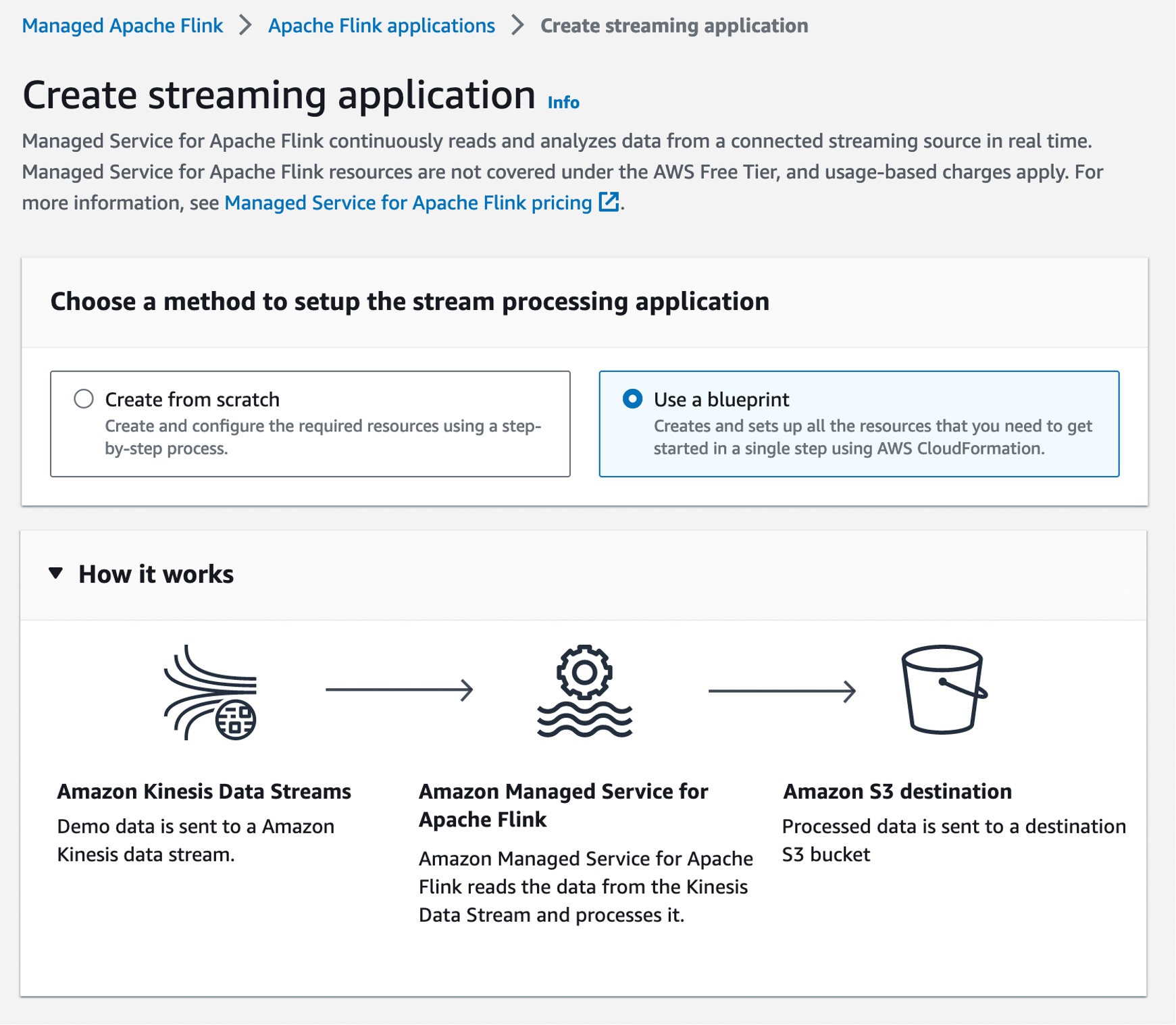
To create a streaming application in the new console, choose Create from scratch or Use a blueprint. With a new blueprint option, you can create and set up all the resources that you need to get started in a single step using AWS CloudFormation.
The blueprint is a curated collection of Apache Flink applications. The first of these has demo data being read from a Kinesis Data Stream and written to an Amazon Simple Storage Service (Amazon S3) bucket.
After creating the demo application, you can configure, run, and open the Apache Flink dashboard to monitor your Flink application’s health with the same experiences as before. You can change a code sample in the GitHub repository to perform different operations using the Flink libraries in your own local development environment.
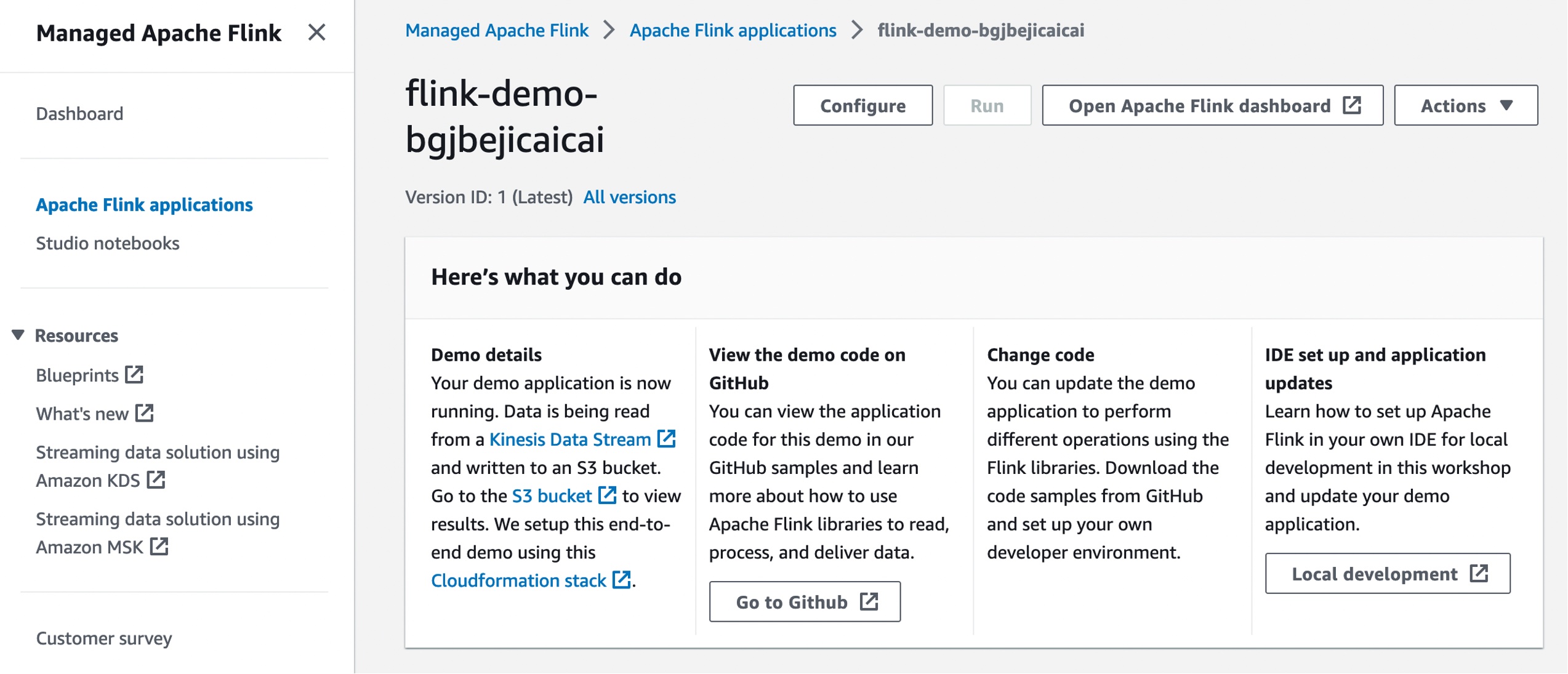
Blueprints are designed to be extensible, and you can leverage them to create more complex applications to solve your business challenges based on Amazon Managed Service for Apache Flink. Learn more about how to use Apache Flink libraries in the AWS documentation.
You can also use a blueprint to create your Studio notebook using Apache Zeppelin as a new setup option. With this new blueprint option, you can also create and set up all the resources that you need to get started in a single step using AWS CloudFormation.
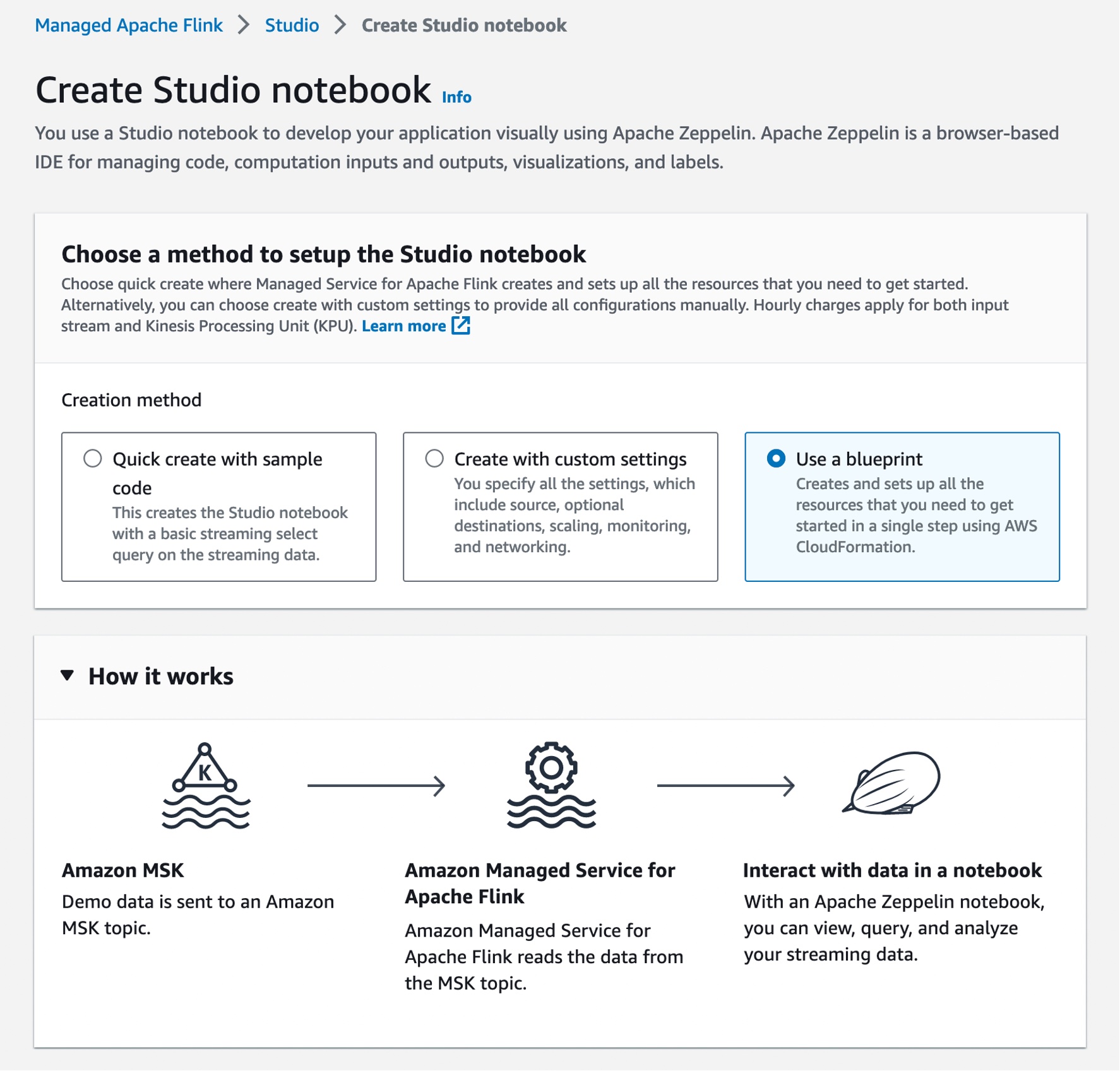
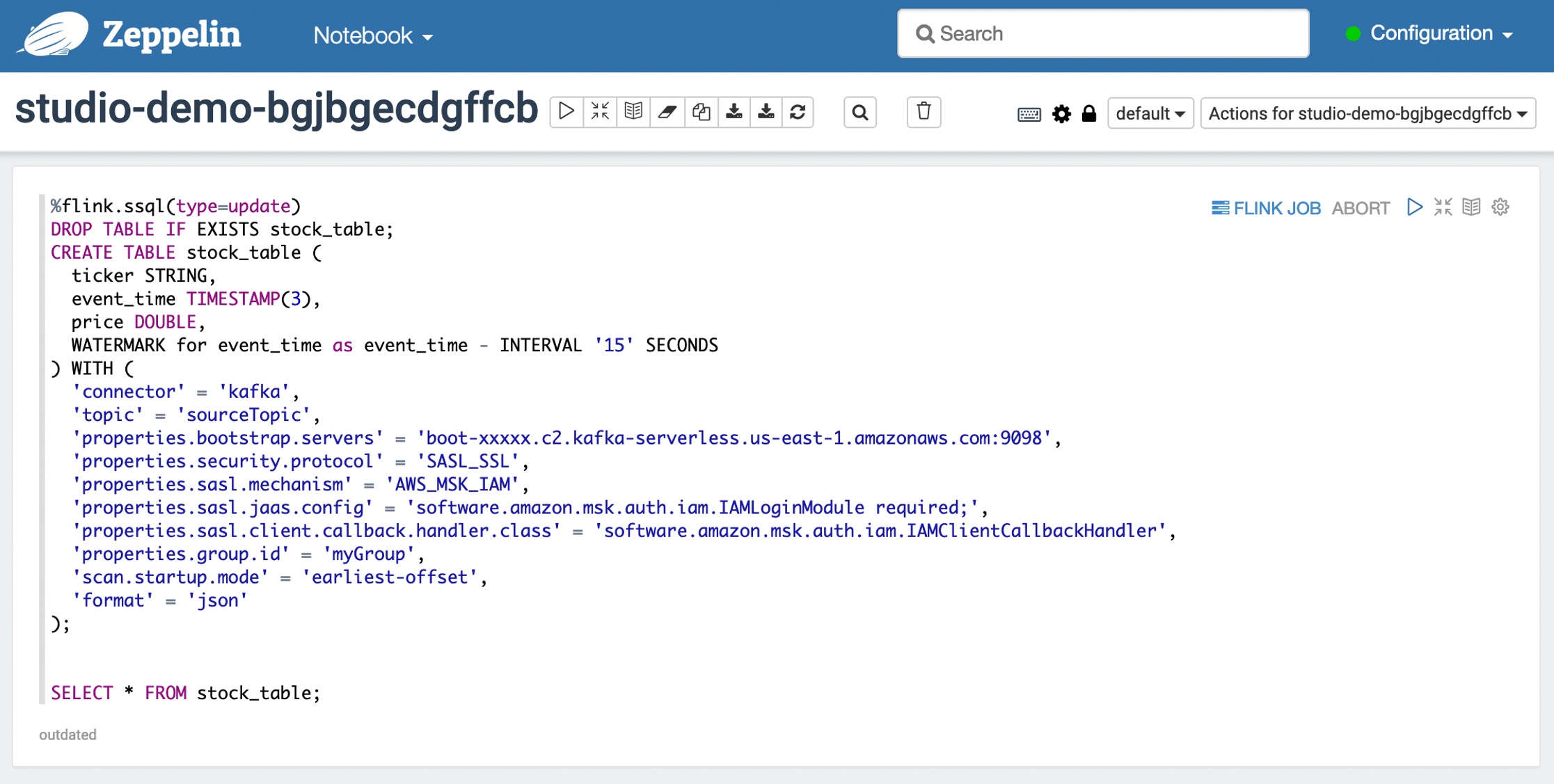
This blueprint includes Apache Flink applications with demo data being sent to an Amazon MSK topic and read in Managed Service for Apache Flink. With an Apache Zeppelin notebook, you can view, query, and analyze your streaming data. Deploying the blueprint and setting up the Studio notebook takes about ten minutes. Go get a cup of coffee while we set it up!
After creating the new Studio notebook, you can open an Apache Zeppelin notebook to run SQL queries in your note with the same experiences as before. You can view a code sample in the GitHub repository to learn more about how to use Apache Flink libraries.
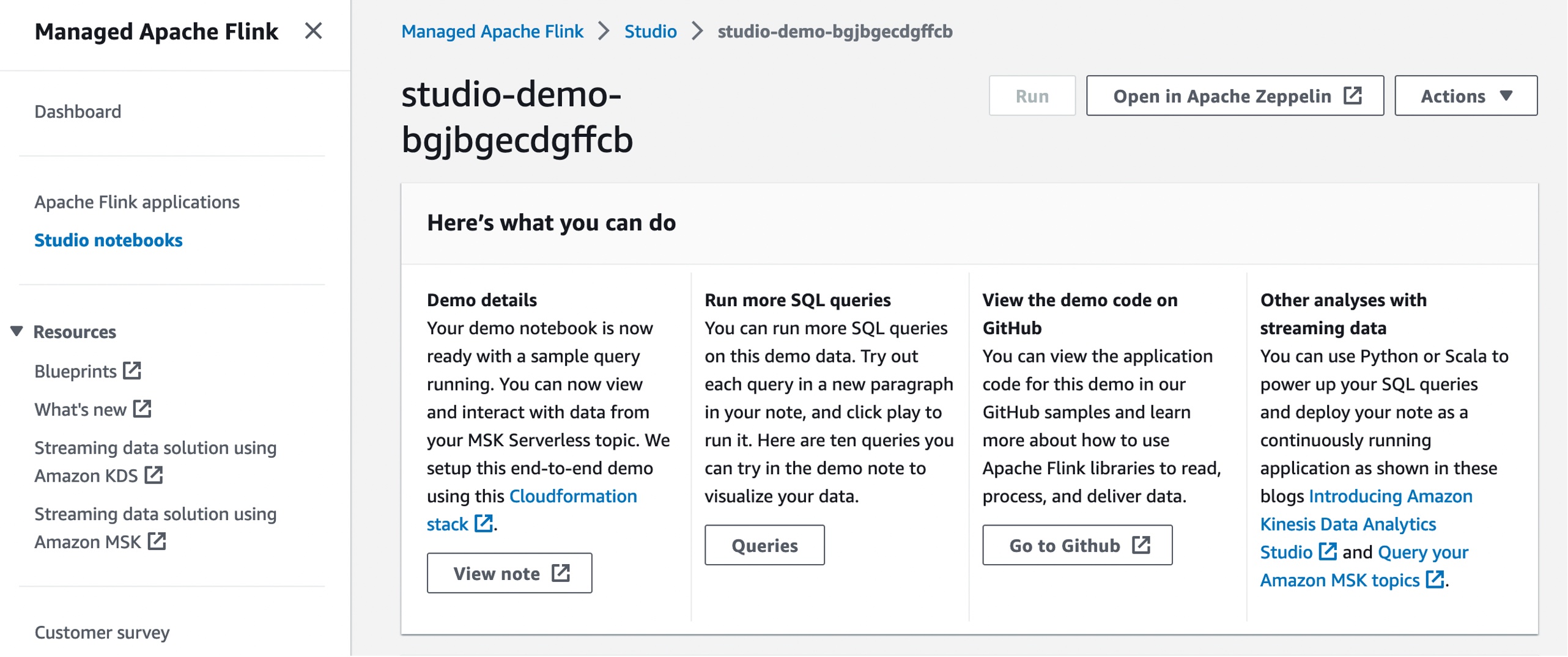
You can run more SQL queries on this demo data such as user-defined functions, tumbling and hopping windows, Top-N queries, and delivering data to an S3 bucket for streaming.
You can also use Java, Python, or Scala to power up your SQL queries and deploy your note as a continuously running application, as shown in the blog posts, how to use the Studio notebook and query your Amazon MSK topics.
To learn more blueprint samples, see GitHub repositories such as reading from MSK Serverless and writing to Amazon S3, reading from MSK Serverless and writing to MSK Serverless, and reading from MSK Serverless and writing to Amazon S3.
Now Available
You can now use Amazon Managed Service for Apache Flink, renamed from Amazon Kinesis Data Analytics. All your existing running applications in Kinesis Data Analytics will work as is without any changes.
To learn more, visit the new product page and developer guide. You can send feedback to AWS re:Post for Amazon Managed Service for Apache Flink, or through your usual AWS Support contacts.
— Channy




